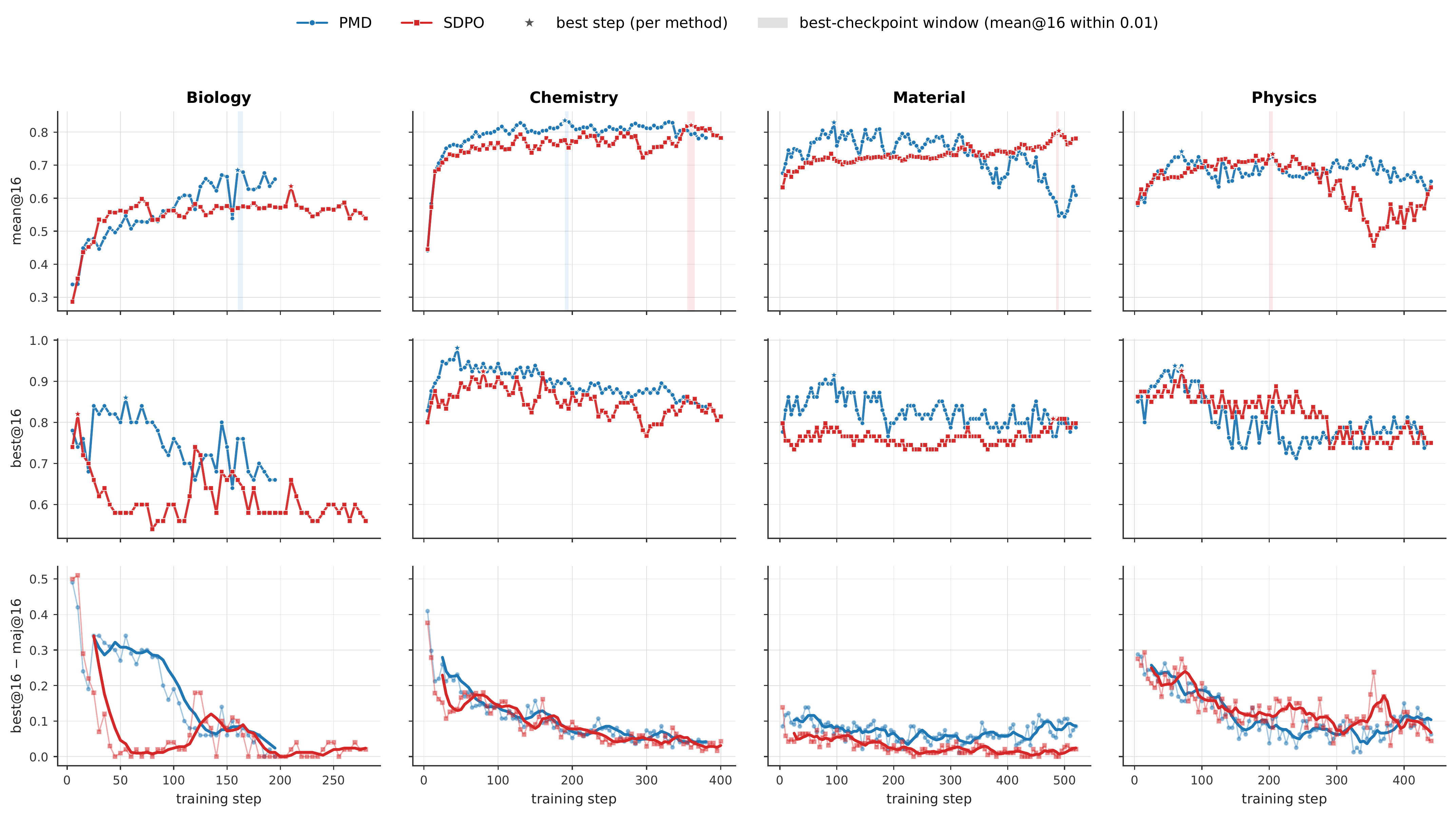
PMD Overview
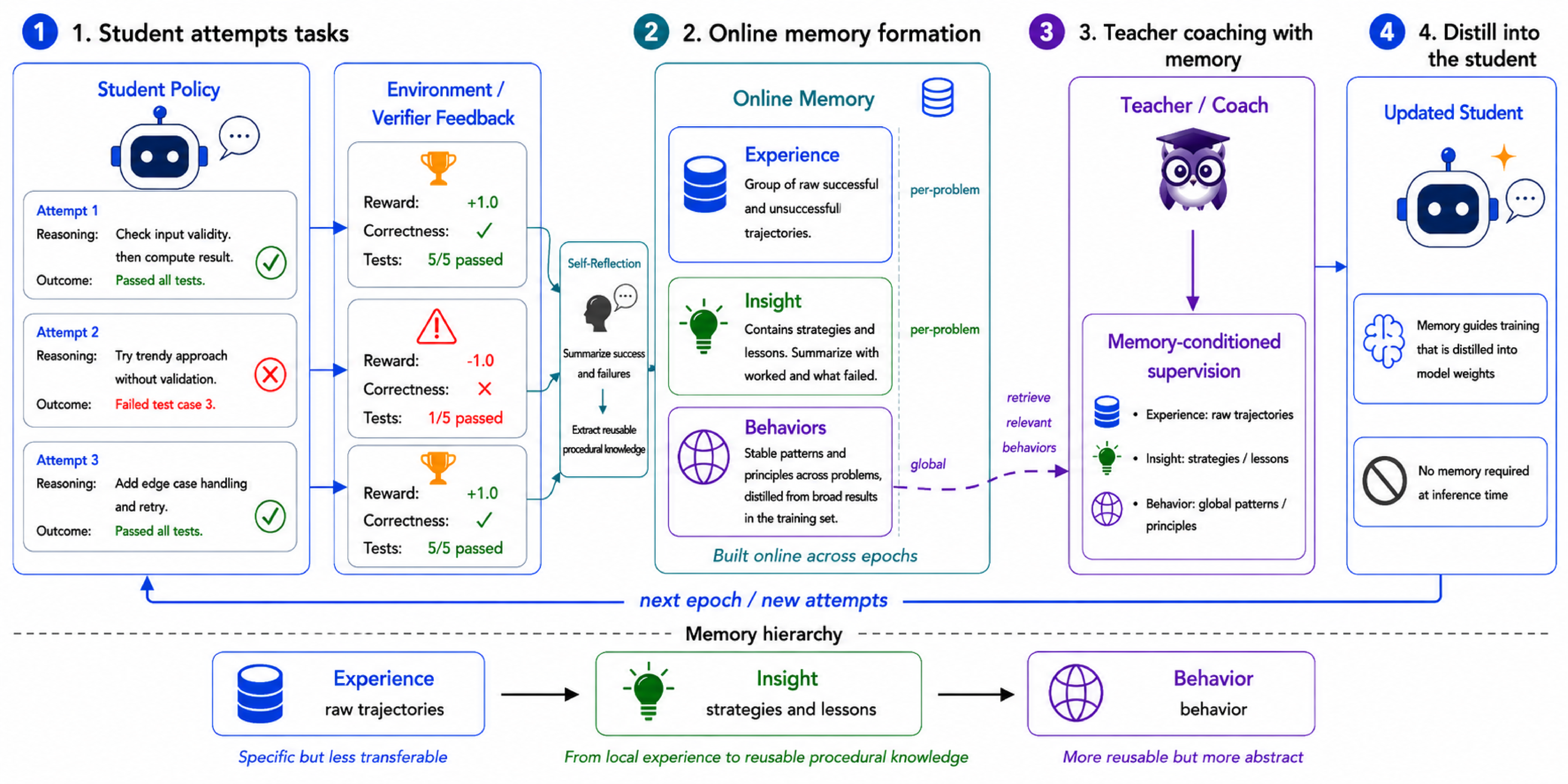
Figure 1: Overview of Procedural Memory Distillation. The student makes attempts and receives verification, self-reflection builds procedural memory at three levels, the memory-conditioned teacher provides supervision, and guidance is distilled into the student for the next epoch.